


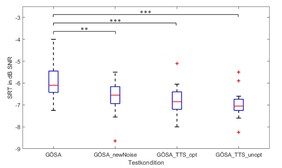
Sprachtests sind ein wichtiger Bestandteil von audiometrischen Testverfahren. Sie geben Auskunft über das Sprachverstehen in unterschiedlichen Situationen, ob in einfachen, ruhigen- oder in komplexen räumlichen Situationen. Um einen Sprachtest zu erstellen, bedarf es einer aufwendigen Auswahl des Sprachmaterials sowie einer entsprechenden Aufnahme eines Sprechers\einer Sprecherin. Danach muss das aufgenommene Signal bearbeitet werden, um ein perzeptiv möglichst ausgewogenes Sprachmaterial für den Sprachtest zu erhalten. Dieser hohe Aufwand ist eine Motivation, eine zeit- und kostengünstigere Alternative zu finden, Sprachmaterial zu generieren bzw. zu erweitern. Im Rahmen des Projektes wurde in der Studie der Göttinger Satztest (GÖSA) betrachtet. Mit dem Text-to-Speech-System der Google-Cloud wurde Sprachmaterial für verschiedene Konditionen erstellt. Die Sprachverständlichkeitsschwelle (engl. Speech Recognition Threshold, SRT) der einzelnen Konditionen wurden verglichen, um eine mögliche Erweiterung des Sprachmaterials des GÖSA durch ein Text-to-Speech-System zu überprüfen. Die verschiedenen Konditionen lauten:
- GÖSA: originales Sprachmaterial + originales Rauschen goenoise
- GÖSA_newNoise: originales Sprachmaterial + aus diesem Sprachmaterial generiertes Rauschen
- GÖSA_TTS_unopt: unoptimiertes synthetisiertes Sprachmaterial + aus diesem Sprachmaterial generiertes Rauschen
- GÖSA_TTS_opt: synthetisiertes Sprachmaterial optimiert in Sprechgeschwindigkeit, Grundfrequenz und Aussprache + aus diesem Sprachmaterial generiertes Rauschen
Aufgrund der im Jahr 2020 herrschenden Covid-19-Situation wurden die Messungen bei den Versuchspersonen Zuhause mit privatem Messequipment durchgeführt. Um einen angenehmen Messpegel zu gewährleisten, wurde zuerst der Most Comfortable Level für Sprache der jeweiligen Versuchspersonen ermittelt.
Ein statistisch signifikanter Unterschied zwischen natürlicher und synthetisierter Sprache konnte nachgewiesen werden (s. Abb. 1), welcher jedoch auf die unterschiedliche Maskierungswirkung des Störgeräusches zurückzuführen ist. Insgesamt zeigen die Ergebnisse dieser Studie, dass die Erstellung der GÖSA-Sätze mit dem Text-to-Speech-System von Google möglich ist und diese in der Sprachaudiometrie nutzbar sind.